爬虫是什么
这里引用一下 wiki 中关于 网络爬虫的定义,相信大家看过后会有一个清晰的认识
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
网络搜索引擎等站点通过爬虫软件更新自身的网站内容或其对其他网站的索引。网络爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引供用户搜索。
爬虫访问网站的过程会消耗目标系统资源。不少网络系统并不默许爬虫工作。因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”。 不愿意被爬虫访问、被爬虫主人知晓的公开站点可以使用robots.txt文件之类的方法避免访问。这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理。
互联网上的页面极多,即使是最大的爬虫系统也无法做出完整的索引。因此在公元2000年之前的万维网出现初期,搜索引擎经常找不到多少相关结果。现在的搜索引擎在这方面已经进步很多,能够即刻给出高质量结果。
爬虫还可以验证超链接和HTML代码,用于网络抓取(参见数据驱动编程)。

爬虫的核心
分析目标网站的数据格式 这一步中我们需要仔细分析目标网站的html格式,寻找它们的内在联系,(如果是异步加载的数据处理起来比较麻烦一点,此处我们不做讲解),找出规律
编写对应的代码爬取 第二步我们需要伪造好我们的目标网站需要的请求头部分,同时根据第一步的规律解析出你想要的数据,然后保存即可

示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
| package photo;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
public class CrawlSophoto {
public static List<String> getImgSrc(String url) throws Exception{
List<String> imgSrcList = new ArrayList<String>();
Document document = Jsoup.connect(url).get();
Elements elements = document.getElementsByTag("img");
String srcUrl;
for (int i = 0; i < 7; i++){
srcUrl = elements.get(i).attr("src");
imgSrcList.add(srcUrl);
}
return imgSrcList;
}
public static void saveImage(List<String> imgSrcList){
String path = "E:\\本地图片\\爬虫图片\\20191110\\";
File file = new File(path);
if (!file.exists()){
file.mkdir();
}
HttpURLConnection httpURLConnection = null;
InputStream inputStream = null;
System.out.println("开始下载图片...");
for (String src : imgSrcList){
try {
URL url = new URL(src);
httpURLConnection = (HttpURLConnection) url.openConnection();
httpURLConnection.setRequestProperty("Cookie", "opqopq=0c01989c7413e5a5d21e68f310c397b5.1573377223; _S=03b161a0b5b7eaaadd261490c514a29d; __guid=16527278.863313966117013800.1573377222710.2178; count=1; tracker=; test_cookie_enable=null");
httpURLConnection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36");
inputStream = httpURLConnection.getInputStream();
OutputStream outputStream = new FileOutputStream(new File(path + new Date().getTime() + ".jpg"));
byte[] bytes = new byte[2048];
int len = 0;
while ((len = inputStream.read(bytes)) != -1) {
outputStream.write(bytes, 0, len);
}
}catch (Exception e){
System.out.println( "src为: " + src + " 的图片下载出错..." + e.getMessage());
continue;
}
}
System.out.println("下载图片完成...");
}
public static void main(String[] args){
String url = "https://image.so.com/";
try {
List<String> imgSrcList = getImgSrc(url);
saveImage(imgSrcList);
}catch (Exception e){
System.out.println("测试出错..." + e.getMessage());
}
}
}
|
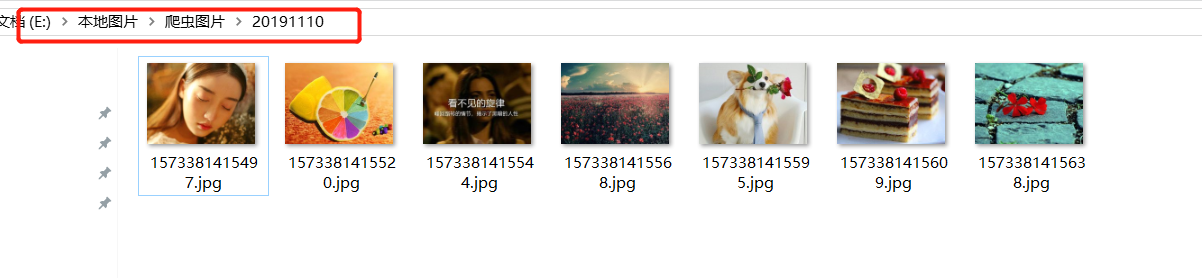
结果展示


摸鱼儿·雁丘词 / 迈陂塘·雁丘词
-- 金朝:元好问
乙丑岁赴试并州,道逢捕雁者云:“今旦获一雁,杀之矣。其脱网者悲鸣不能去,竟自投于地而 死。”予因买得之,葬之汾水之上,垒石为识,号曰“雁丘”。 同行者多为赋诗,予亦有《雁丘词》。旧所作无宫商,今改定之。
问世间,情为何物,直教生死相许?
天南地北双飞客,老翅几回寒暑。
欢乐趣,离别苦,就中更有痴儿女。
君应有语:渺万里层云,千山暮雪,只影向谁去?
横汾路,寂寞当年箫鼓,荒烟依旧平楚。
招魂楚些何嗟及,山鬼暗啼风雨。
天也妒,未信与,莺儿燕子俱黄土。
千秋万古,为留待骚人,狂歌痛饮,来访雁丘处。




